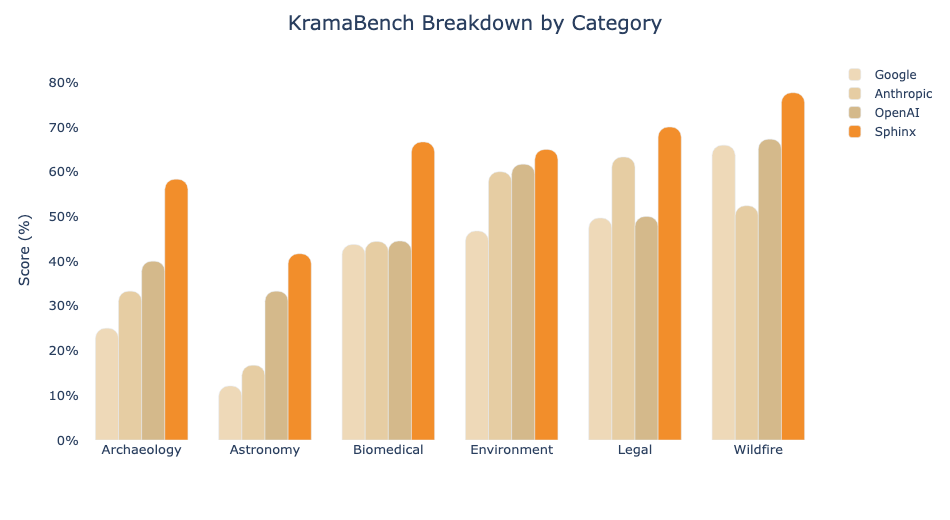
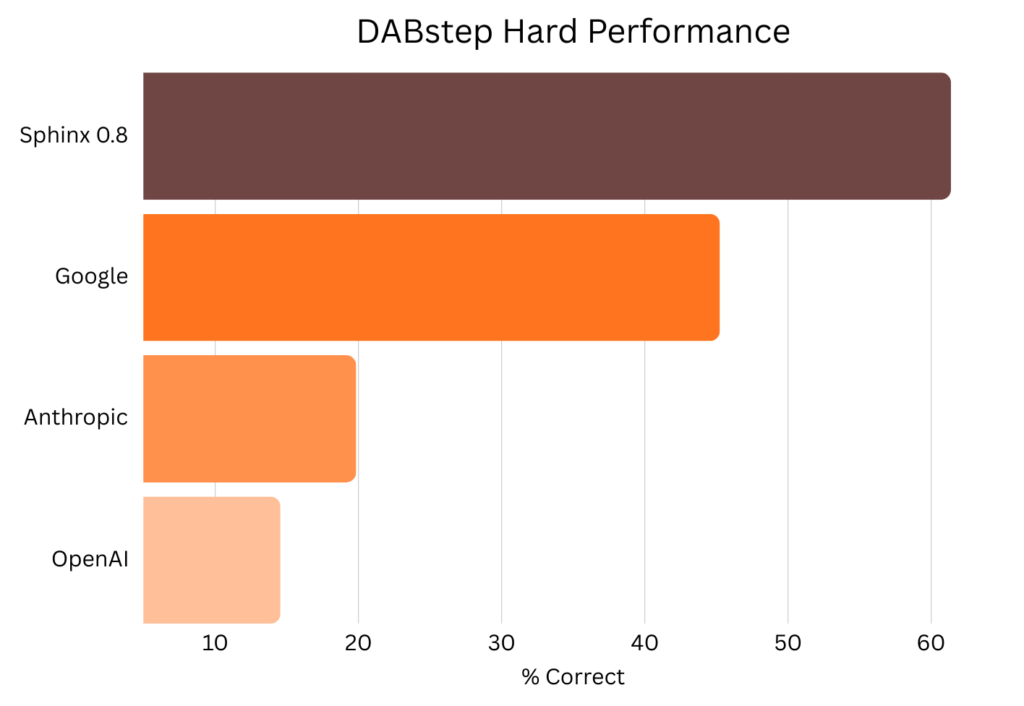
Data science and software engineering are related but distinct fields. Superficial commonalities, like the use of code as the main way to express ideas, are contrasted with significant differences in the thought process and goals.
Software engineering focuses on structure and consistency. Engineers design systems that act predictably under clear requirements, aiming to create products that work the same way every time.
Data science, by contrast, is inherently exploratory and probabilistic. The data scientist is concerned with uncovering patterns, testing hypotheses, and quantifying uncertainty. Instead of deterministic outcomes, the work often produces models that approximate reality, with confidence intervals, error margins, or probabilistic forecasts.
We think tools like Cursor and Claude Code are amazing partners for software engineers (we use them ourselves at Sphinx) but when it comes to data, it’s like using a fork to eat soup — you can pick up a few drops with sufficient skill, but a better tool makes a world of difference. Decisions made using data can carry significant consequences for firms and individuals, and when software agents fail even on simple tasks it’s critical to design AI systems distinctly for data teams.
In this post, we dive into a relatively simple example that makes the divergence clear. Consider some quadratically distributed data, which forms a noisy U-shaped curve:
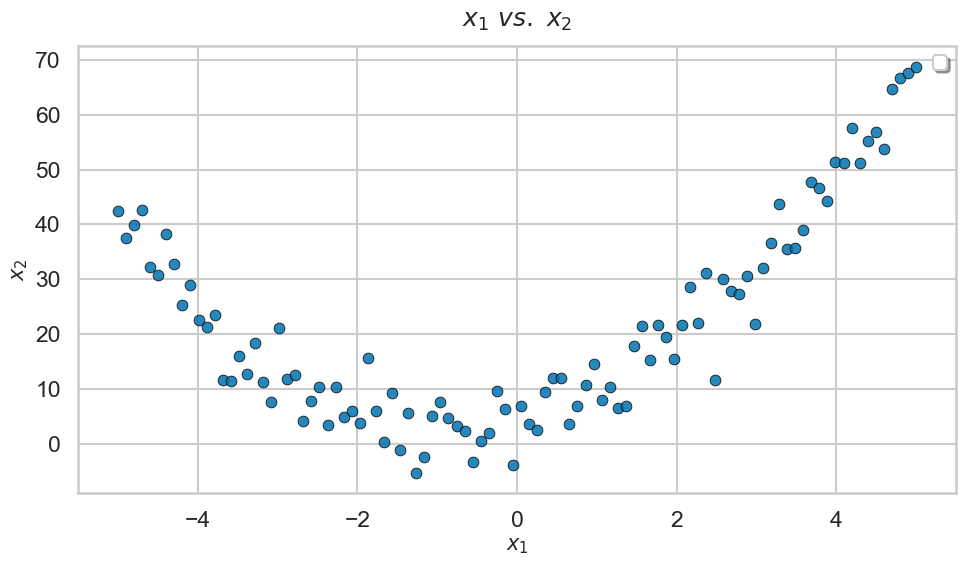
We’ll give this data to two AI agents and ask them to model x2 using x1. To a human data scientist, this is a trivial task — the data is quadratic, so we should fit a degree-2 polynomial curve. Any other model is either too simple or very overfit.
Let’s see what happens when we give this task to Cursor:
Cursor eventually concludes that a degree 3 polynomial is the best model, which is dangerously overfit. There are a few ways in which Cursor’s process is not in line with how a data scientist ought to approach the problem:
Now, we give the same data and problem to Sphinx’s AI Copilot:
Sphinx is able to correctly choose a quadratic model without even fitting anything — like a data scientist, Sphinx builds intuition through exploration to suggest reasonable models. In addition:
Even in simple workflows, the divergence is clear: the software engineer writes code to confirm expected behavior, while the data scientist runs experiments to discover unexpected behavior. One domain is about eliminating uncertainty; the other, about understanding and managing it.
This dichotomy is why Sphinx exists. Agentic systems need to be deeply tied to the inductive biases of how a certain type of workflow should be carried out, and software copilots just don’t cut it in data science.
Sphinx is building the AI layer for data. Try it for free today to see the difference, or reach out to our team for a demo of our enterprise-scale capabilities.