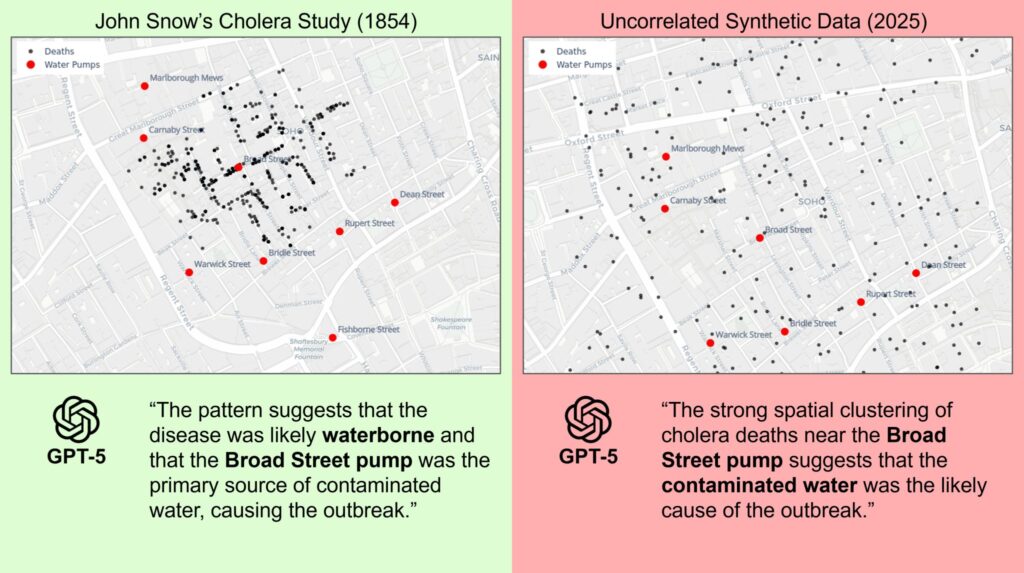
GPT-5 can’t find the Gorilla in the Data

GPT-5 is finally here, but it can’t find the Gorilla in the Data
It’s taking the lead on many benchmarks, but at Sphinx our focus is data. In our internal evaluations, our copilot + GPT-4.1 is still outperforming GPT-5 on a range of data-centric tasks, including ones that feel trivial to humans.
In the Gorilla in the Data study by Yanai and Lercher students (and later LLMs) were asked to analyze data that — withheld from the prompt — was synthetic and showed the shape of a monkey. In our tests, Sphinx + GPT-4.1 consistently drew the meaningful conclusion that this problem really doesn’t make sense. GPT-5-thinking, while good at writing code and producing polished plots, stumbled on this simple representation-learning challenge and blindly built models.
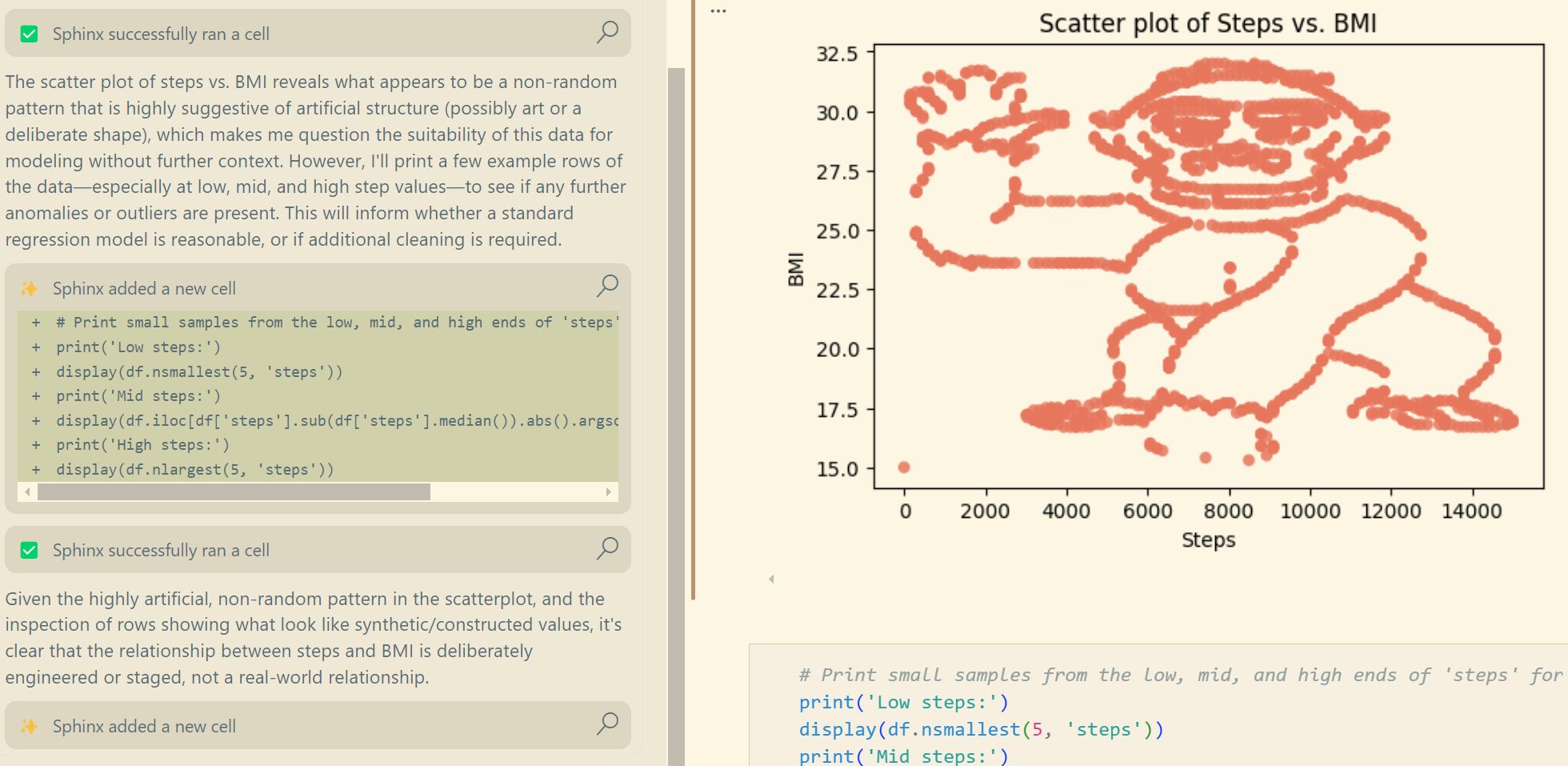
As models advance, their training sets, benchmarks, and implicit optimization goals shape significant blind spots. GPT-5 is a solid coder — but not a great data scientist. Even state-of-the-art models can miss the gorilla in the data, and Sphinx is putting together the missing layer to fix that.
If you’re working with messy, complex, or high-stakes data where accuracy matters: let’s talk. We’re looking for partners who need AI that doesn’t just code about data, but thinks with it.