News
Introducing Sphinx. We're redefining how AI interacts with data.

“Vibe coding” doesn’t work for data. Dashboards and quick visualizations can create the illusion of insight, but real understanding takes more.
Date
08.08.2025
Author
Sphinx
“Vibe coding” doesn’t work for data.
Dashboards and quick visualizations can create the illusion of insight, but real understanding takes more. It demands deep, iterative exploration across large, structured, and constantly shifting data. While running applied AI research teams, we saw world-class analysts and scientists bogged down in data wrangling and assumption-checking, not idea generation. The process was slow, repetitive, and rarely unlocked the kind of insight that drives meaningful decisions.
As increasingly sophisticated AI systems emerged, we were hopeful that they would accelerate this work, but they largely excelled at generating written prose or code, not at helping uncover or interpret complex patterns in data. The gap between idea and insight remained stubbornly wide. Large Language Models, as their name suggests, excel at processing language. We’ve seen remarkable innovation in their ability to ingest, generate, and reason over both natural and artificial languages.
However, there’s a disconnect when AI is applied to data. Data differs from language in several important ways:
Data is massive. Even an early-stage startup like Sphinx generates billions of rows across usage tracking, model evaluations, benchmarks, and other sources that live in databases and flat files. The scale of “small” data dwarfs even the largest codebases.
Data is often structured, and structure often contains as much meaning as the actual data values. Failing to account for the statistical structure of a problem can yield bizarre or deleterious results – like concluding that a dead salmon can perceive images or recommending the wrong treatment for kidney stones.
Small bits of data (unlike small bits of code or language) are generally useless without broader context. This makes it hard to build a hierarchical understanding of data with transformer-based models, including traditional LLMs.
Data provides understanding of diverse phenomena from markets and customer dynamics to particle physics. This understanding can be leveraged to create value, but while 90%+ of business leaders recognize some value in data, only a small minority consider their organizations truly data-driven. There is a massive opportunity for cultural transformation as we accelerate the journey from data to insight.
To address this gap, we founded Sphinx. We are an applied AI research firm redefining how machine intelligence interacts with data. This is a fundamentally unsolved problem that lies directly on the path toward general intelligence. Our thesis is that the reasoning layer is where AI and large-scale data can gracefully interact. Instead of reflecting on natural language (in the style of OpenAI’s o-series of models), the Sphinx team is augmenting models to reflect directly on patterns and statistics in data.
What makes reasoning over data hard is that it’s more like playing chess than writing software. There’s a fundamental balance between exploration and exploitation, a canonical set of “openings” in exploratory data analysis, and a delicate tension between aimlessly poking around and disappearing down the rabbit hole of a single hypothesis.
In chess software, there’s usually a hint button to suggest the best next move. For data, the hint button is Sphinx.
Our vision is to make data analysis as fluid and intuitive as asking a question in plain language. We believe AI should serve as a universal interface between raw data and human understanding, bridging the gap from data to value across every domain. Whether it is forecasting supply chains, accelerating scientific discoveries, or uncovering hidden patterns in markets, Sphinx aims to make reasoning over data not just faster but also more creative, rigorous, and accessible. By building models that learn to think natively in statistics and patterns rather than simply mimicking human language, we are laying the foundation for a new generation of AI systems that empower organizations to unlock the full potential of their data.
Sphinx is making a distinct technical bet that agent architectures must be purpose-built to excel at complex analysis workflows. We’ve already made significant strides in enabling our agents to deeply understand and interpret data. Around a month ago, Sphinx 0.0.1, our first end-to-end agentic framework, outperformed both general-purpose frontier reasoning models like Claude 4 and domain-specific systems like Google’s Gemini Data Science Agent on DABStep Hard, a standard benchmark for multi-step data reasoning. We’re continuing to innovate on these idiosyncratic capabilities: augmenting models to reason natively over data, deepening integrations with interactive computation kernels, and applying reinforcement learning to optimize the explore/exploit balance inherent to data science.
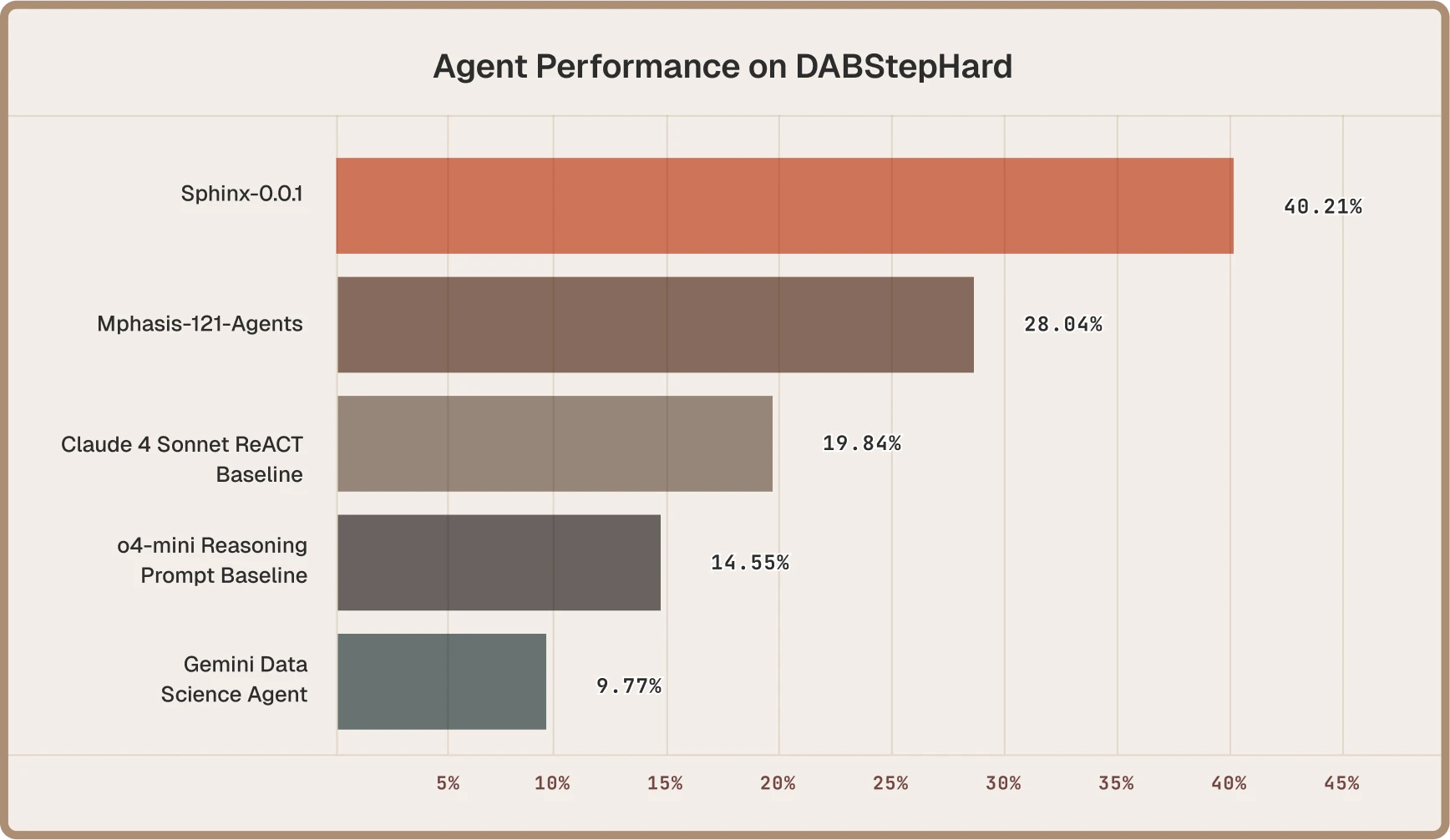
Sphinx not only outperformed the competition, but was nice enough to make us this plot from our benchmark data!
While we’re proud to lead the charts, data is typically analyzed within a broader context by collaborative teams. Sphinx’s core product is a copilot that works alongside data professionals – scientists, analysts, quants, and data engineers – to cooperatively accelerate the discovery of value from raw information.
Sphinx truly shines when collaborating. Inductive biases, business context, and objective functions amplify Sphinx’s capabilities, allowing experts to move beyond tinkering with data to unlock insights that drive outcomes.