DABstep, introduced earlier this year, is one of the best benchmarks we’ve seen for measuring how well agentic AI can reason over complex, messy, heterogeneous data. It mirrors the real enterprise work we do at Sphinx: cross-referencing inconsistent sources, executing multi-step workflows with nontrivial dependencies, and delivering answers in a range of formats. We’re grateful to Adyen and Hugging Face for helping build the academic foundations that underpin our research and, ultimately, the product we deliver to users.
Unfortunately, as of this Monday, we learned of a leakage issue that exposed DABstep test-set answers. This undermines the benchmark’s reliability for comparative evaluation across agents. We plan to preserve our results up to the point of the leak and will continue leveraging DABStep internally for ongoing validation and testing.
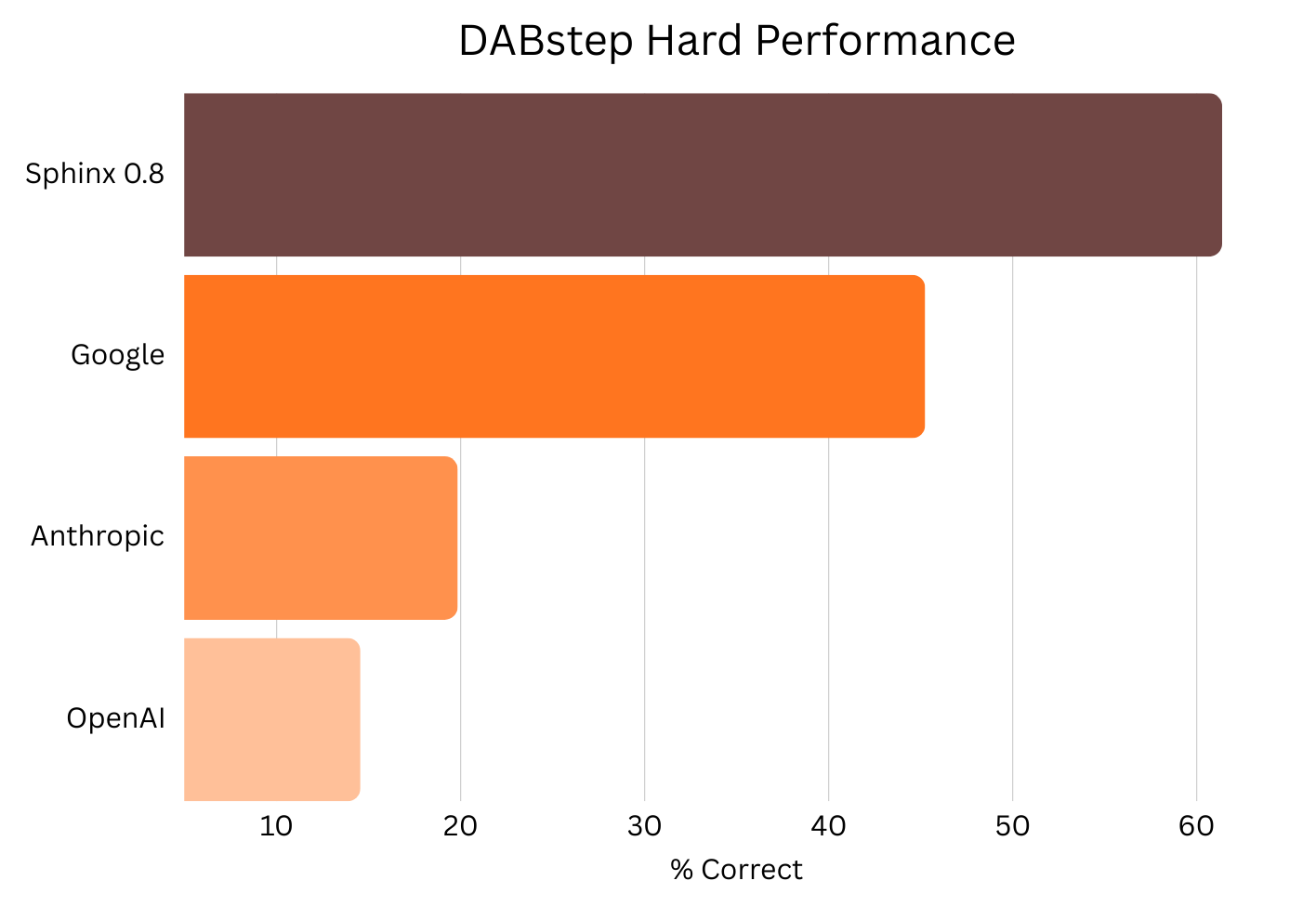
Sphinx’s Performance as of the DABstep Leak
We released Sphinx version 0.8 a short while before the test set was exposed — Sphinx achieved accuracy over 61%, up around 20% since our first release. This beats out Google, OpenAI and Anthropic-based agents. There were several innovations that gave us this boost:
- Improvements to EDA: Sphinx is more able to explore the tree of options on how to solve a data science problem. This includes backtracking/failing-fast when something doesn’t work, exploring multiple paths, and flagging inconsistent or messy parts of the data that may pose a problem later in the analysis. We’ve exposed our best-in-class EDA tooling as plan mode in Sphinx’s UI, so you can leverage the agent to collaboratively develop a robust plan to solve your data science tasks.
- Better Data Representation: We’ve improved how Sphinx internally understands data types, allowing us to more accurately understand anomalies and unusual patterns that need to be accounted for — for example, dealing with mixed-type columns with values like
10, 10.31, "<10"and "between 10 and 14".
- Understanding External Context: Sphinx is more responsive and thoughtful when accounting for domain knowledge provided by the user (in the case of DABstep, a sheet of definitions and clarifications provided with the benchmark). In addition to improving benchmark performance, this change means that Sphinx can better account for your business context and logic when working alongside you.
What’s Next after DABstep
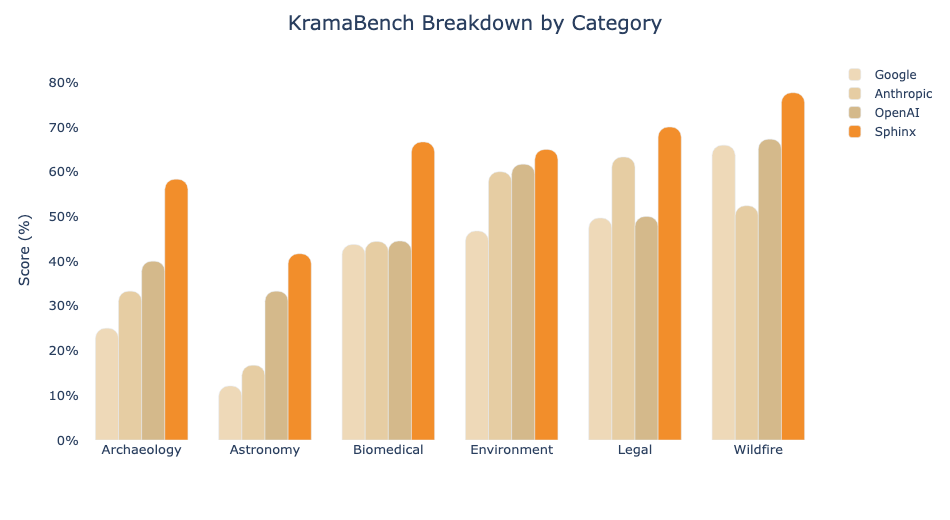
We’ll continue using DABStep as one of several internal benchmarks, and we’re actively evaluating emerging academic benchmarks as potential substitutes. Our evaluations need to reflect the realities of enterprise data: large-scale, untidy, and highly heterogeneous across data types. The tasks also need to be genuinely hard: spanning multiple sources, requiring business-logic understanding, and demanding a high bar for precision. Without that, “benchmark optimization” won’t translate into a better product experience for our users.
As we continue to explore public benchmarks, Sphinx is also building an internal evaluation suite grounded in the hardest problems we’ve encountered so far. This suite serves as our gold standard, ensuring our agent keeps making meaningful progress towards becoming the best-in-class data scientist. We’ll be sharing more about this benchmark in the coming weeks!