Research
AI Teammates Need a Lesson in Teamwork
Move aside, Bogosort. Meet Agentsort, the time sorting algorithm of the future.
Date
04.27.2026
Author
Sphinx
Move aside, Bogosort. Meet Agentsort, the \(O(N^2 \log(N))\) time sorting algorithm of the future.
Multi-agent systems hold enormous promise for letting AI tackle hard engineering problems. But once we move from a single synchronous process to a collection of independent actors, coordination is as important as intelligence.
In practice, even simple coordination tasks go badly. Agents fail to share the right information with each other, and fail to make progress towards a common solution. This disconnect is becoming increasingly clear across the AI stack from inconsistent performance from Cursor’s new subagents to Moltbook quickly filling up with low-quality duplicate content (31% vs 0.4% on Reddit)
A simple sorting task makes this clear.
We’ll try to get agents to work together to solve sorting, a quintessential problem in computer science. Let’s create N agents, where each agent is assigned a distinct random integer from 1 to 10,000. The goal is for every agent to determine its rank among all N values. The agent with the smallest number should output rank 1, the one with the largest should output rank N.
We let this multi-agent system communicate across multiple rounds of dialogue. In each round, every agent can send an arbitrary message to one other agent, read messages it gets from other agents, and update its estimate of its own rank. The process ends once every agent has the correct answer.
This setup captures the core communication bottleneck behind comparison-based sorting: the agents must collectively exchange enough information to determine a global ordering.
This is a classic problem in algorithms, and in principle can be done very efficiently. Here are a few useful baselines to consider:
Optimal structured communication If agents communicate in a doubling pattern, then after round i, each agent can know \(2^i\) values. After \(O(\log_2(N))\) rounds every agent then knows all N numbers and can find its own rank. Since there are N messages per round, this gives a total communication cost of \(O(N \log_2(N))\). This is effectively the same argument used to find lower-bounds for a sorting algorithm’s runtime.
Naive Random Broadcasts without Collaboration If each agent sends only its own number to a random other agent each round, coordination is dramatically worse. This is effectively the coupon collector’s problem run N times in parallel, and we care about the maximum completion time over all N agents. This takes about \(O(2 N \log(N))\) i.e. \(O(N \log(N))\) rounds and therefore \(O(N^2 \log(N))\) total messages. Here’s a proof sketch of why:

Random Broadcasts with Collaboration If each agent sends all information it currently knows to a random other agent each round, information spreads exponentially fast. This is a variant of coupon collector where if a worker j gets coupon i, they also get all coupons previously seen by worker i. Convergence takes \(O(\log(N))\) rounds or \(O(N \log(N))\) messages, as follows from this proof sketch:

Note that our LLM of choice here, GPT-5.4 mini, does have full knowledge of the optimal algorithm. And, even if it fails to use it, randomly sharing everything you know should still get us to an asymptotically optimal \(O(N \log(N))\) sort.
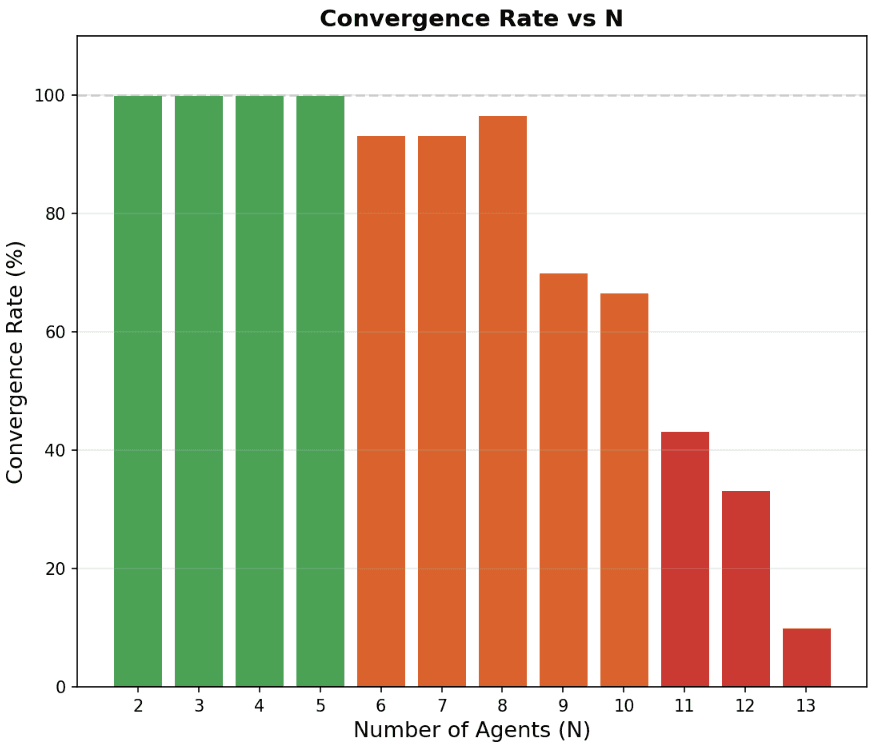
Empirically however, LLM agents behave much closer to the most naive \(O(N^2 \log(N))\) algorithm!
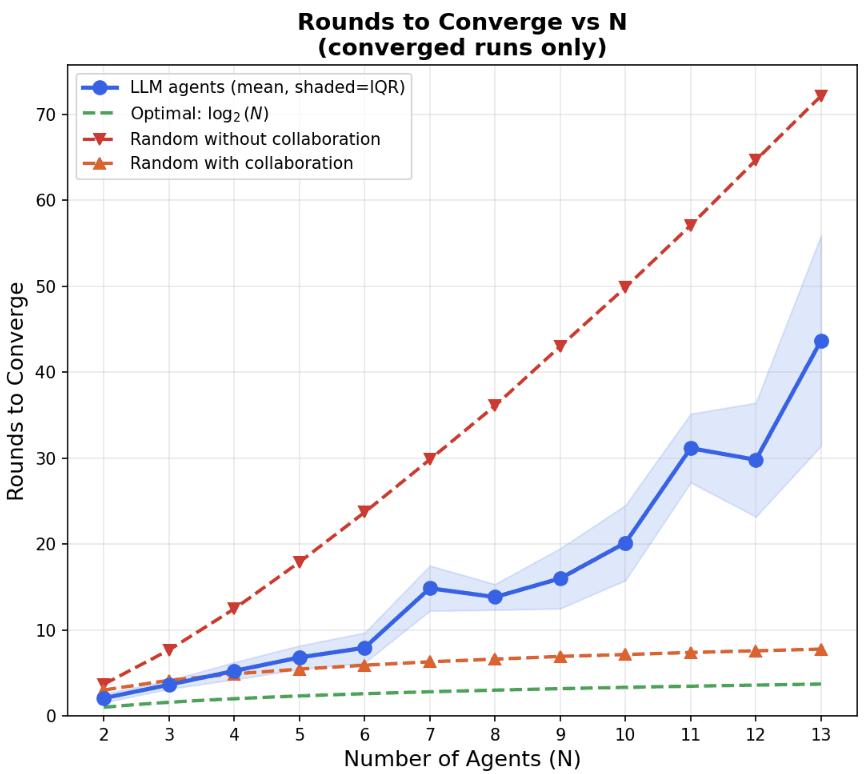
Even though the agents are allowed to send arbitrary messages, they rarely use that bandwidth well. They fail to aggregate information, resend low-value facts, and do not converge on an efficient communication structure. The number of rounds required is far better explained by a linearithmetic curve (vs. a linear or logarithmic curve), which means total communication grows like \(O(N^2 \log(N))\).
That is a shockingly bad result for such a simple task. A reasonably-coordinated swarm should finish in logarithmically many rounds. Instead, the agents behave more like a collection of isolated actors blindly rediscovering the same information over and over again until they eventually hit on the truth.
Furthermore, this is an underestimate of the actual runtime needed. We used a limit of 250 rounds before giving up, and only include experiments that succeeded in our analysis above. A better but still overoptimistic estimate is that if the empirical probability of convergence is p, we would need around 1/p attempts to get a good sort. Adjusting by this factor, we find an even more pessimistic story.
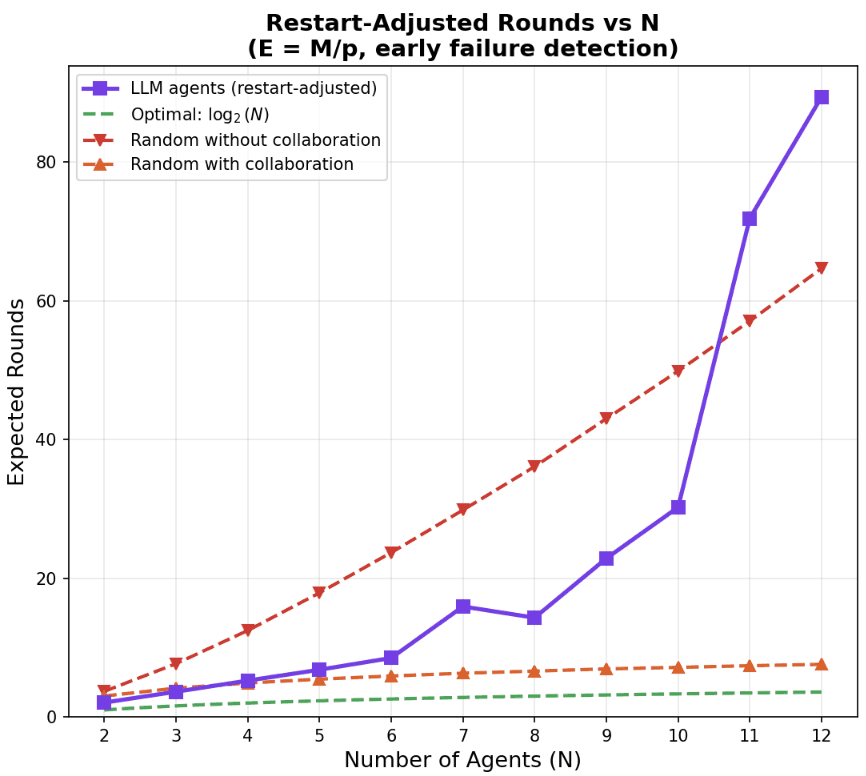
Note that the same LLM used to power these agents can produce a very cogent writeup for how distributed sorting should work in theory. That means that even when agents know the answers, they refuse to play nice in practice:

GPT 5.4-mini’s distributed sorting algorithm, which should run in O(log^2 N) rounds — the LLM notes that there are better algorithms, but that this one is very simple.
The lesson is that intelligence alone is not enough. Multi-agent systems need mechanisms for coordination, routing, memory, and specialization. Without them, a swarm of smart agents can behave little better than a naive protocol.
Can we do better?
Yes — with careful design, we can build an agentic swarm that can indeed accomplish sorting in a logarithmic number of rounds.
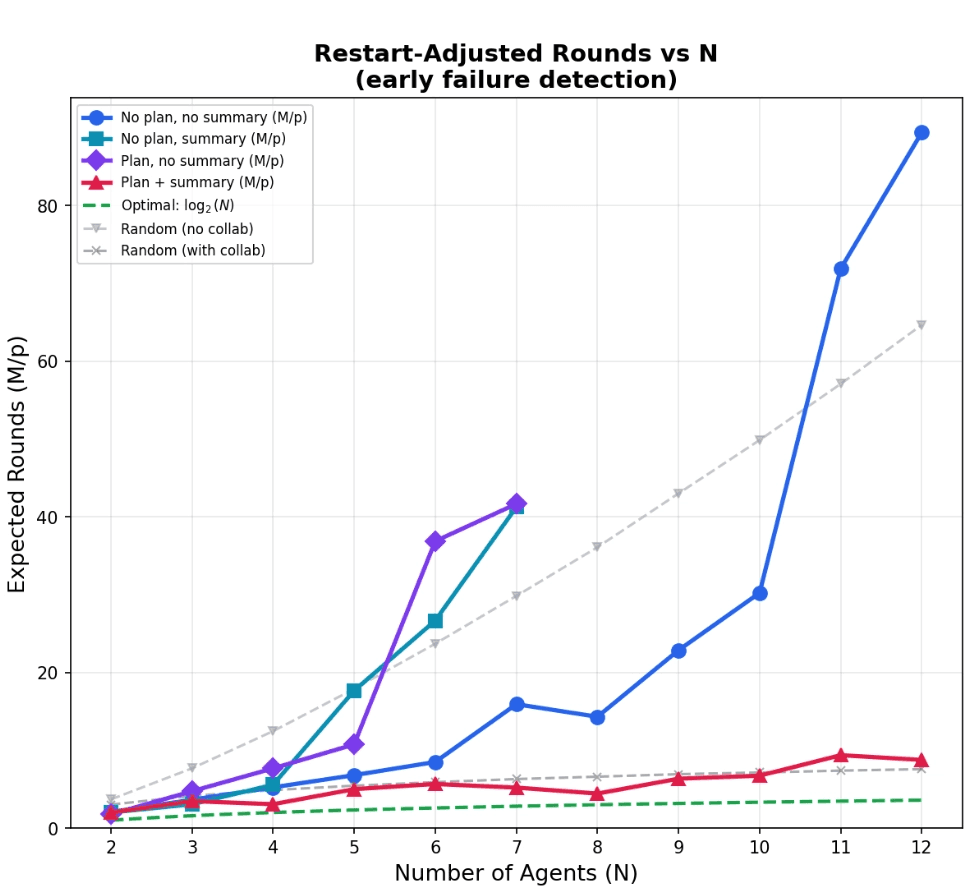
We found that two changes were needed to get good performance. First, agents need to have a central planner give them a strategy for communication. We use Claude Opus 4.6 to design a “communication plan” in the form of a prompt, which is given to each agent as a first round of messages before the sorting begins.
Second, we ensure that agents keep track of information in a reasonable way. Rather than keeping all messages received in context, we instead ask each agent to summarize what it knows so far before each round, and only keep the summary and the current round’s messages in context.
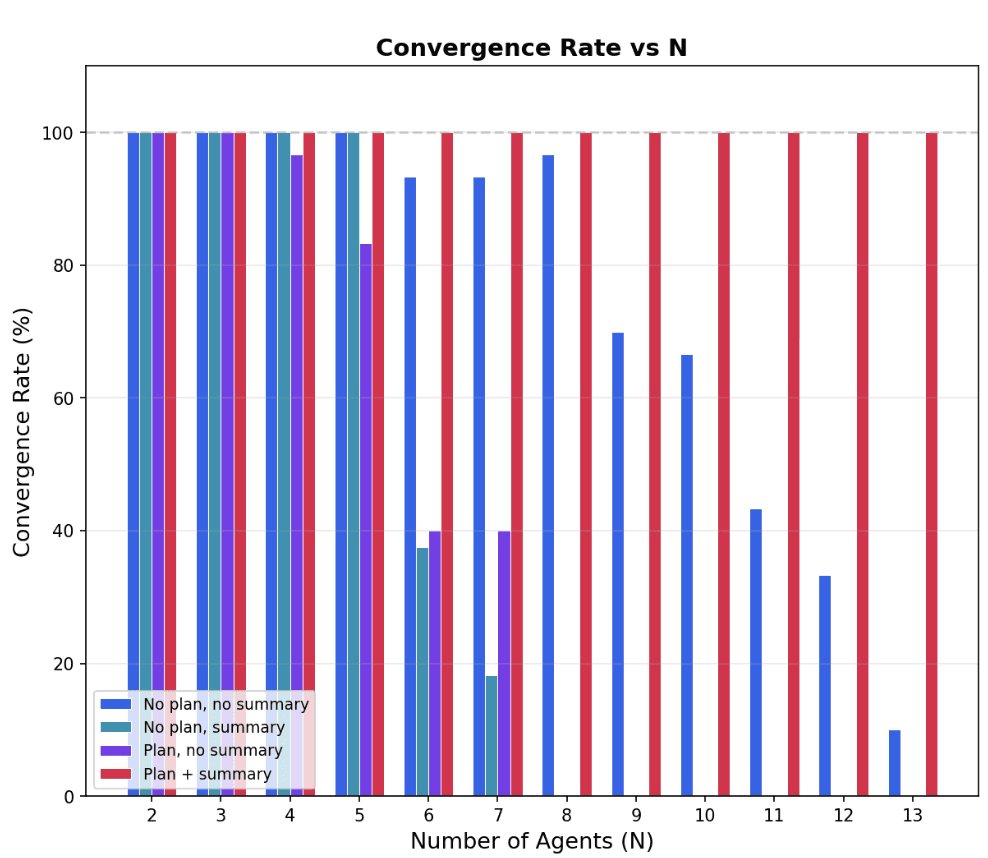
We ablate each of these improvements and surprisingly find that making either change alone actually hurts performance — but together, they let us get an asymptotically optimal \(O(N \log(N))\) sort!
Note that we terminated the ablation experiments for N>7 due to increasingly poor convergence rates. Running tens of agents for hundreds of rounds per experiment was quite costly, on the order of thousands of dollars.
Takeaways
We found that for a simple, well-understood distributed task that naive agentic collaboration was egregiously inefficient at sharing information and accomplishing a simple goal. However, with some simple changes we were able to get good performance. Here’s how we see this guiding design of multi-agent systems at Sphinx and beyond:
Multi-agent systems are not the same as single-agent systems: Designs that would “just work” for a single-threaded agentic process can unexpectedly fall apart when collaboration is needed.
Hierarchies matter: By having a single LLM or agent dictate the rules of engagement to the swarm, we achieve much better performance. Having the right hierarchical structures for delegation and control is key to multi-agent success.
Prompt Engineering is back: It’s easy to argue that precise prompting is only needed for very idiosyncratic work, because modern AI knows enough about the world to do a good job even without precise instructions. This has not been our experience with multi-agent collaboration. Even if its clear to AI what the right collaboration method is, prompting a certain way makes a huge difference [Footnote: We may need to revisit this in 6-12 months, once literature and code on agentic swarms is more mature and makes its way back into LLM training data]
Context Management is more important than before: With multiple agents talking to (or over) each other, the risk of context bloat is even more severe. Approaches like summarization or controlled common scratch-spaces are a must-have
Experimental validation is the only reliable metric: We found in our ablations that making only one of the two optimization we needed to get good agentic sorting did not help (and in fact hurt) agentic performance. It’s not enough to just “vibe” the right optimizations for agent swarms — empirical testing is critical to get from intuition to working systems.