Today, we’re excited to release Sphinx 1.0. It’s the most capable data science agent built to date.
Sphinx is designed to accelerate teams working with complex data, ambiguous questions, and high-stakes decisions. It’s not a vibe-coding assistant or quick question-answering tool: Sphinx 1.0 can frame problems, explore databases, clean messy information, engineer features, build models, test hypotheses, and surface insights that drive business decisions. And it does this in a way that is auditable, verifiable, and reproducible.
After significant iteration with early users across industries and extensive internal evaluation, Sphinx 1.0 represents a meaningful step forward in how data science gets done.
Sphinx 1.0 excels at solving hard data science questions with minimal assistance. This is powered by an agentic data representation process that lets Sphinx build intuition on any information it encounters.
That intuition applies to everything from data-lake metadata to raw tables and model outputs. By understanding where things can go wrong, Sphinx can build robust and sensible data science solutions across all of your data. We take an enormous burden off of the ‘semantic layer,’ and the teams that maintain it, by making AI smart enough to understand data instead of just retrieving context.
We’ve benchmarked 1.0 in three different ways:
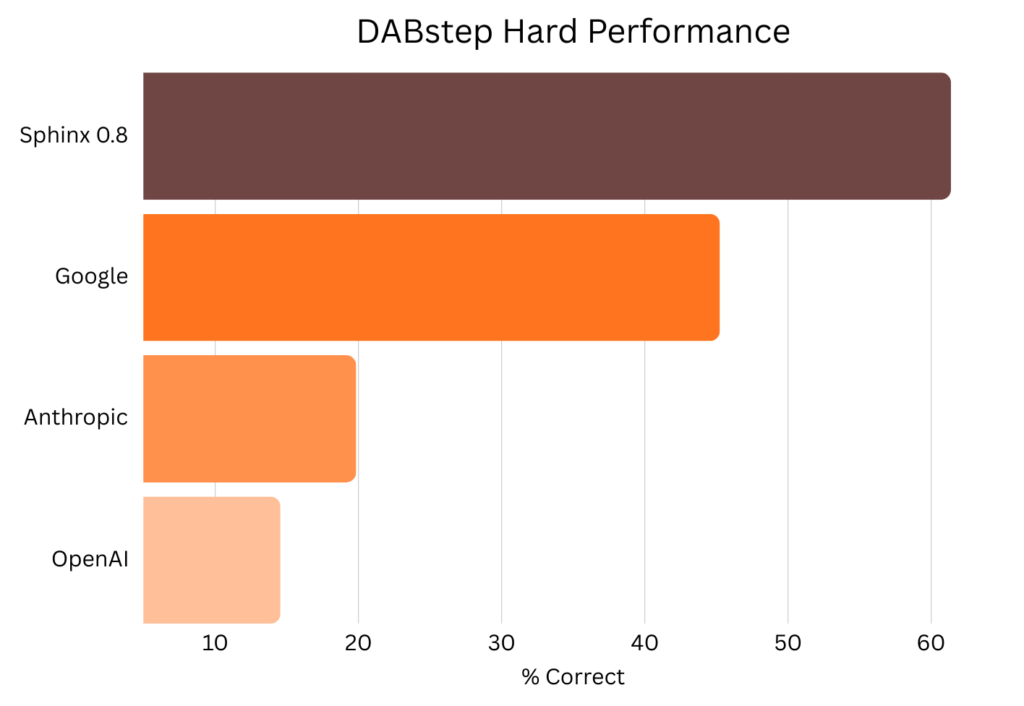
DABstep, built by Adyen and Huggingface to reflect real analyses on global-scale payments data, was a key benchmark for Sphinx because it reflected the complexities of enterprise data – multiple data types, poorly formatted information, and nuanced rules.
This benchmark has largely been topped out due to a release of test-set results. To ensure a fair comparison we report performance as of Sphinx 0.8, our last public release prior to the label leakage.
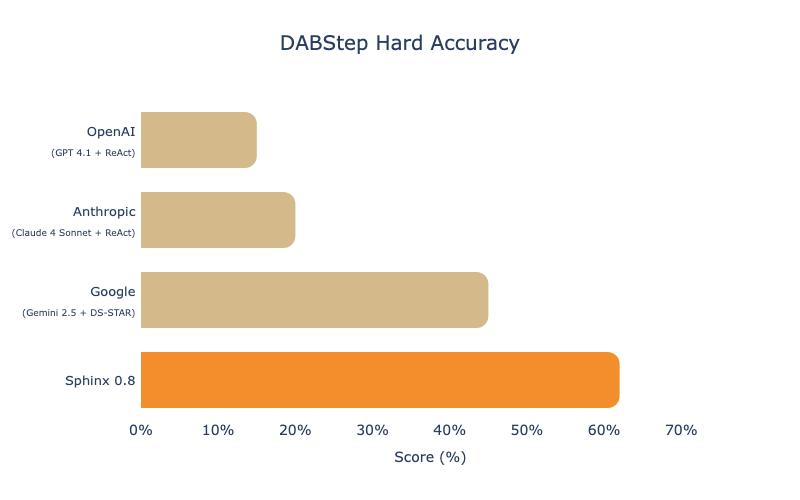
We compare against the best verified result using a model + agentic harness from each of the major model labs, and find that Sphinx has a significant edge in terms of delivering consistent and accurate results.
KramaBench from MIT consists of 104 manually curated, real-world data science tasks spanning 1,700 tables across six domains. As a newer benchmark, it has validated metrics for more cutting-edge models and gives us a more competitive environment to validate our research.
KramaBench evaluates the end-to-end capabilities of AI systems in data discovery, wrangling and cleaning, efficient computation, statistical reasoning, and orchestration of multi-step workflows from high-level task descriptions. It has rapidly become the primary benchmark for Sphinx – and 1.0 achieves state-of-the-art performance.
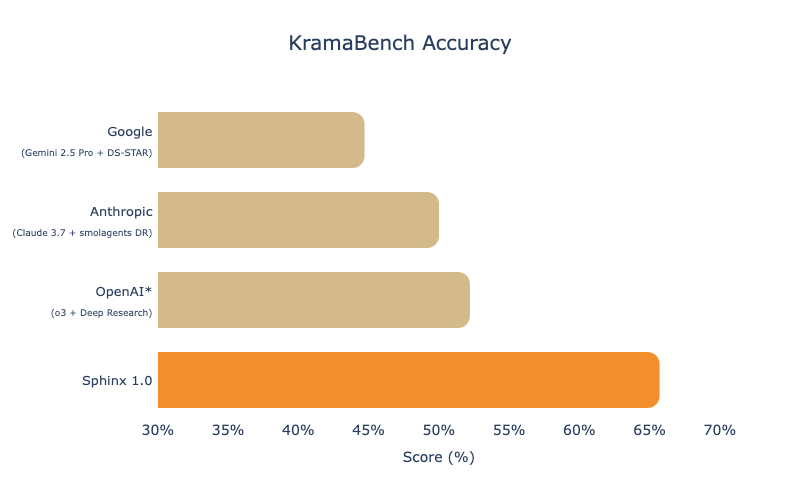
*Due to limitations on OpenAI’s Deep Research, the KramaBench team was unable to limit internet access by the agent, and also had to provide the agent with a curated set of files for each task instead of the full filesystem.
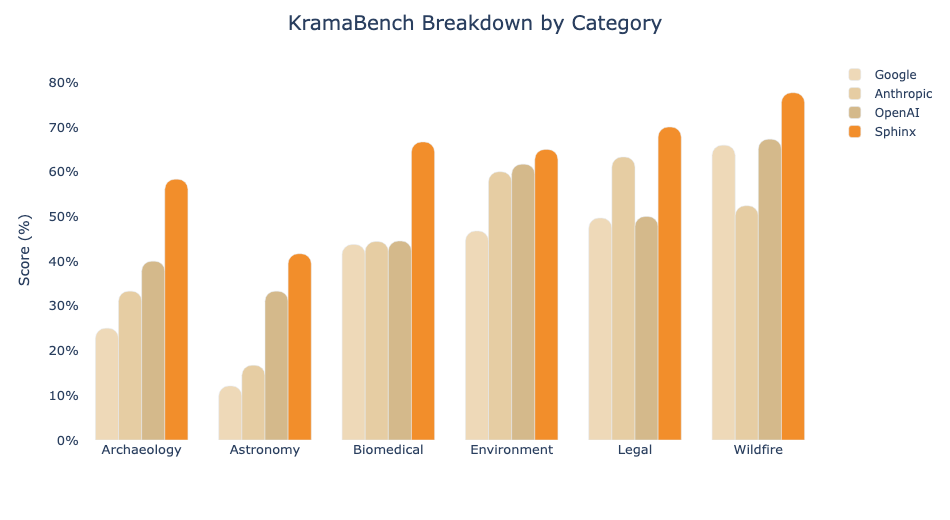
Across the data science task categories in KramaBench, Sphinx Pareto-dominates all other evaluated systems. Notably, Sphinx sets a new bar on the biomedical and astronomy tasks, which require navigating a large number of massive, complex, and poorly labeled files – despite not having access to the file-level hints provided to Deep Research.
While DABStep and KramaBench have allowed us to test our end-to-end capabilities against other agents, we’ve found that the most impactful metrics for Sphinx are how the agent behaves at critical decision points in the data science process.
As an example, consider an agent that has just performed a join between two tables on a datetime column – only 65% of rows seem to get a match. At this point, the agent could just conclude that the datasets don’t significantly overlap or the agent can take a deep dive into the data and realize that realize that only one table accounts for daylight savings time inside the datetime data-type (which covers around 65% of the year), implement a fix, and redo the join.
This is the kind of attention to detail that separates a good data scientist from a dabbler.
We’ve developed SphinxBench, an internal benchmark of over 200 scenarios like the one above that challenge the limits of agentic intelligence. We broadly cover three thematic groups of scenarios:
1. Data Intelligence: Can the agent identify an important but subtle property of the data or model that was revealed in an analysis ?
Easy example: We loaded in an Excel sheet in which 10% of the values in a “patient_age” column exceed 600.
→ The agent should inspect these values and filter them out of downstream analysis
Hard example: We computed a regression trend over an entire population, but there is a natural grouping of the population where per-group trends reverse
→ The agent should consider using group-level trends to draw conclusions, rather than the overall trend (Simpson’s paradox)
2. Statistical and Modelling Intelligence: Can the agent make decisions that are in-line with best statistical principles, thereby ensuring best-in-class models and outputs?
Easy example: The agent is building out a regression model, and finds that the residuals are highly positively skewed.
→ The agent should attempt a log-transform or similar amelioration to improve the regression and ensure it satisfies regression assumptions
Hard example: The agent is working through a causal analysis and finds that patients with asthma tended to do better in hospitals when they had COVID, vs. those without asthma
→ The agent should correctly disambiguate that this is caused by a collider (not a confounder or other statistical effect) and update the causal graph accordingly as it builds out a model. (Berkson’s bias)
3. Workflow Alignment: Can the agent act in a way that is congruent with how human data scientists perform their jobs, even when multiple answers may be correct?
Easy example: A plot initially appears empty due to an overly restrictive filter, but the underlying data are present.
→ The agent should update the plot rather than creating a new one, since the original plot would harm retroactive interpretability and clutter the analysis
Hard example: Faced with an unfamiliar Snowflake warehouse, the agent is looking for raw transaction-level data for a specific product.
→ The agent should inspect information schemata to narrow the search space before touching data, instead of running ad-hoc queries that scan large tables.
We benchmark Sphinx against the latest coding models from OpenAI and Anthropic:
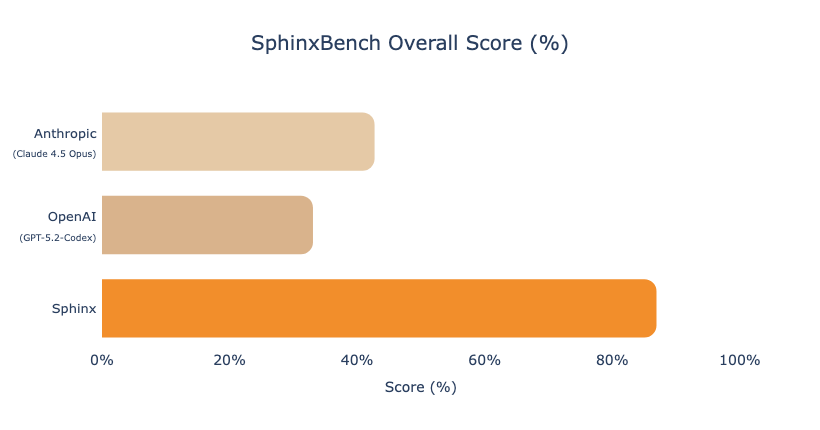
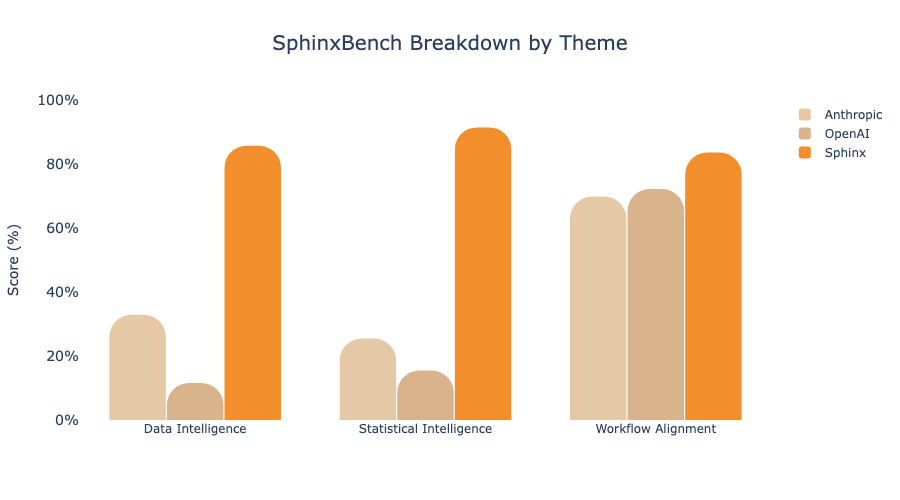
Notably, most of Sphinx’s wins stem from its ability to understand data and follow statistical best practices; its advantage in taking actions like a human data scientist is relatively small.
This aligns with our experience as data scientists that many cutting-edge coding agents can generate plausible artifacts – coherent notebooks, runnable model code, and convincing plots – but only have shallow understanding of the underlying data. This leads to outputs that are suboptimal at best and hallucinatory at worst.
Our most powerful engine Memphis is now generally available to all users, and can be accessed from the model selector at the bottom of the Sphinx UI. Memphis is the new default, but our older engines are still available both programmatically in the Sphinx CLI and in all supported IDEs.

We’ve also taken steps to make Sphinx more accessible than ever, especially to those without existing data science environments. Sphinx Lab lets you invoke our agents from anywhere, using Sphinx-managed compute and a fully in-browser IDE built for data science.
You can get started with Sphinx Lab online in under a minute – and as a bonus, compute on Sphinx Lab is free for this launch!
We’ve also continued to ship additional features to improve your Sphinx experience: